
For the last few months we have been computing and publishing daily forecasts of COVID-19 cases and deaths in Brazil. This is a partnership with a team of professors from the Pontifical Catholic University of Rio de Janeiro and the Getulio Vargas Foundation. The website is in Portuguese. The results can be found in https://covid19analytics.com.br/.
Basic Quantile Regression
By Gabriel Vasconcelos
Introduction
Today we are going to talk about quantile regression. When we use the lm command in R we are fitting a linear regression using Ordinary Least Squares (OLS), which has the interpretation of a model for the conditional mean of 

Structural Analisys of Bayesian VARs with an example using the Brazilian Development Bank
By Gabriel Vasconcelos
Introduction
Vector Autorregresive (VAR) models are very popular in economics because they can model a system of economic variables and relations. Bayesian VARs are receiving a lot of attention due to their ability to deal with larger systems and the smart use of priors. For example, in this old post I showed an example of large Bayesian VARs to forecast covariance matrices. In this post I will show how to use the same model to obtain impulse response coefficients and perform structural analysis. The type of estimation was based on Bańbura et al. (2010) and the empirical application is from Barboza and Vasconcelos (2019). The objective is to measure the effects of the Brazilian Development Bank on investment. Therefore, we will measure how the investment respond to an increase in loans over the time.
Posted in R
Tagged BNDES, Brazil, insightr, R, R blog, Structural VAR, VAR, Vector Autorregressive
7 Comments
Benford’s Law for Fraud Detection with an Application to all Brazilian Presidential Elections from 2002 to 2018
By Gabriel Vasconcelos and Yuri Fonseca
The intuition
Let us begin with a brief explanation about Benford’s law and why should it work as a fraud detector method. Given a set of numbers, the first thing we need to do is to extract the first digit of each number. For example, for (121,245,12,55) the first digits will be (1,2,1,5). Perhaps our intuition would say that for a large set of numbers, each first digit, from 1 to 9, would appear in equal proportion, that is 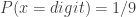
BooST series II: Pricing Optimization
By Gabriel Vasconcelos & Yuri Fonseca
Introduction
This post is the second of a series of examples of the BooST (Boosting Smooth Trees) model. You can see an introduction to the model here and the first example here. Our objective in this post is to use the derivatives of the BooST to obtain prices that maximize the profit for a given set of products. We will use a very simple setup that we know the true optimal prices to compare with the estimated prices. The tricky thing here is that the demand functions we defined are for substitute products. Therefore, if we increase the price of product A it will affect positively the demand for product B.
Posted in R
Tagged BooST, boosting, Demand, insightr, Pricing, R, R blog, Regression Trees
6 Comments
Growing Objects and Loop Memory Pre-Allocation
By Thiago Milagres
Preallocating Memory
This will be a short post about a simple, but very important concept that can drastically increase the speed of poorly written codes. It is very common to see R loops written as follows:
v = NULL n = 1e5 for(i in 1:n) v = c(v, i)
This seems like a natural way to write such a task: at each iteration, we increase our vector v to add one more element to it.
BooST series I: Advantage in Smooth Functions
By Gabriel Vasconcelos and Yuri Fonseca
Introduction
This is the first of a series of post on the BooST (Boosting Smooth Trees). If you missed the first post introducing the model click here and if you want to see the full article click here. The BooST is a model that uses Smooth Trees as base learners, which makes it possible to approximate the derivative of the underlying model. In this post, we will show some examples on generated data of how the BooST approximates the derivatives and we also will discuss how the BooST may be a good choice when dealing with smooth functions if compared to the usual discrete Regression Trees.
Posted in R
Tagged BooST, boosting, Derivatives, insightr, Machine Learning, Nonlinear, Partial Effects, R, R blog
3 Comments
BooST (Boosting Smooth Trees) a new Machine Learning Model for Partial Effect Estimation in Nonlinear Regressions
By Gabriel Vasconcelos and Yuri Fonseca
We are happy to introduce our new machine learning method called Boosting Smooth Trees (BooST) (full article here). This model was a joint work with professors Marcelo Medeiros and Álvaro Veiga. The BooST uses a different type of regression tree that allows us to estimate the derivatives of very general nonlinear models. In other words, the model is differentiable and it has an analytical solution. The consequence is that now we can estimate partial effects of a characteristic on the response variable, which provide us much more interpretation than traditional importance measures.
Posted in Publications, R
Tagged BooST, boosting, Derivatives, insightr, Machine Learning, Nonlinear, Partial Effects, R, R blog
12 Comments
ArCo in the R Journal
The (Artificial Counterfactual) ArCo package is now fully described in a paper in the R Journal (click here). There you can find details about the model, examples and applications on simulated and real data and a comparison with the Synthetic Control.
Introducing the HCmodelSets Package
By Henrique Helfer Hoeltgebaum
Introduction
I am happy to introduce the package HCmodelSets, which is now available on CRAN. This package implements the methods proposed by Cox, D.R. and Battey, H.S. (2017). In particular it performs the reduction, exploratory and model selection phases given in the aforementioned reference. The software supports linear regression, likelihood-based fitting of generalized linear regression models and the proportional hazards model fitted by partial likelihood.
